Computational Solutions Through Co-Design
Elizabeth Singer

Background
Computational Solutions through Co-Design began with the goal of retrofitting my grandmother's home, adapting to her evolving needs as she aged and faced new disabilities, prioritizing personalization and acknowledging the difference in perspectives of the caretakers and the users. My grandma and I began creating solutions that reflected her specific desires for her specific disabilities in her specific environment and situation. Embedding technology into her environment to enhance her independence and quality of life.
When my grandmother passed away, the project had to pivot. The goals remained the same: to use technology to empower close family members with disabilities through co-designing for one specific person, environment, and situation. Instead of doing multiple designs to transform my grandma’s home, since that was no longer possible, I decided to do three case studies for three different people close to me.
Now more than ever, we can access vast computational resources in hand-held devices or remotely through a simple API call—resources that can support machine learning applications both remotely and locally. This allows for the accessible customization of solutions on an individual basis, beyond what was previously possible.
My user-initiated and designed-for-one approach contrasts with one-size-fits-all solutions, emphasizing personalization and user-generated ideas.
Living with a disability offers a unique lens for innovation, serving as a continuous testbed for new ideas. The project aims to enhance independence with personalized technological integrations into home environments. This endeavor was personal and rooted in creating for my loved ones, addressing real problems with tangible solutions.
Case Studies
The three case studies detailed in this project are:
- "Driving Assistant" Traffic Light Detection for Color Blindness: This involved creating a system to help an individual with red-green color blindness navigate traffic signals safely. The user wanted to know if a traffic light was red, yellow, or green and to be alerted of stop signs. The solution used a combination of hardware (a single-board computer with a camera) and software (AI-driven object detection) to identify traffic lights and alert the user through audio cues.
- "Bill Counter" Assistive Money Counter for Limited Vision and Cognitive Disabilities: This focused on an individual who also faced challenges with dimentia and vision. The user wanted to know how much money they had. The solution was developing a computer vision system was developed to recognize and count currency, providing audio feedback to the user about the total amount.
- "Reading Assistant" Sign and Text Overlay for Limited Vision with Speech to Text: Developed a system to aid an individual with limited vision and cognitive disabilities in reading complex signs and printed material. The user wanted to be able to read their mail. By employing optical character recognition and a language model for simplification and summarization, the system provided both visual and auditory outputs to make the content accessible.
Driving Assistant
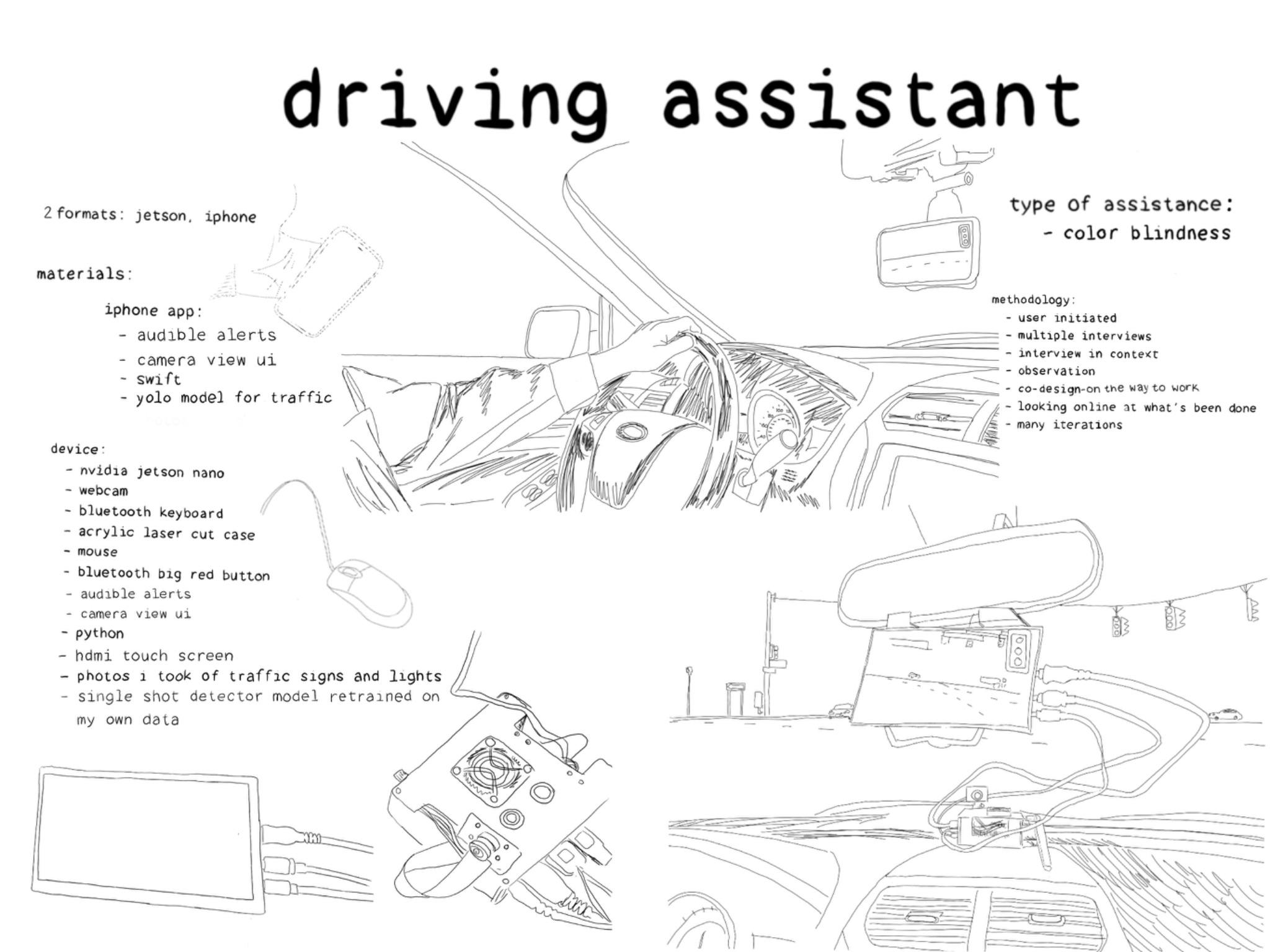

Collaborator: Adam (Name has been changed for privacy)
Problem
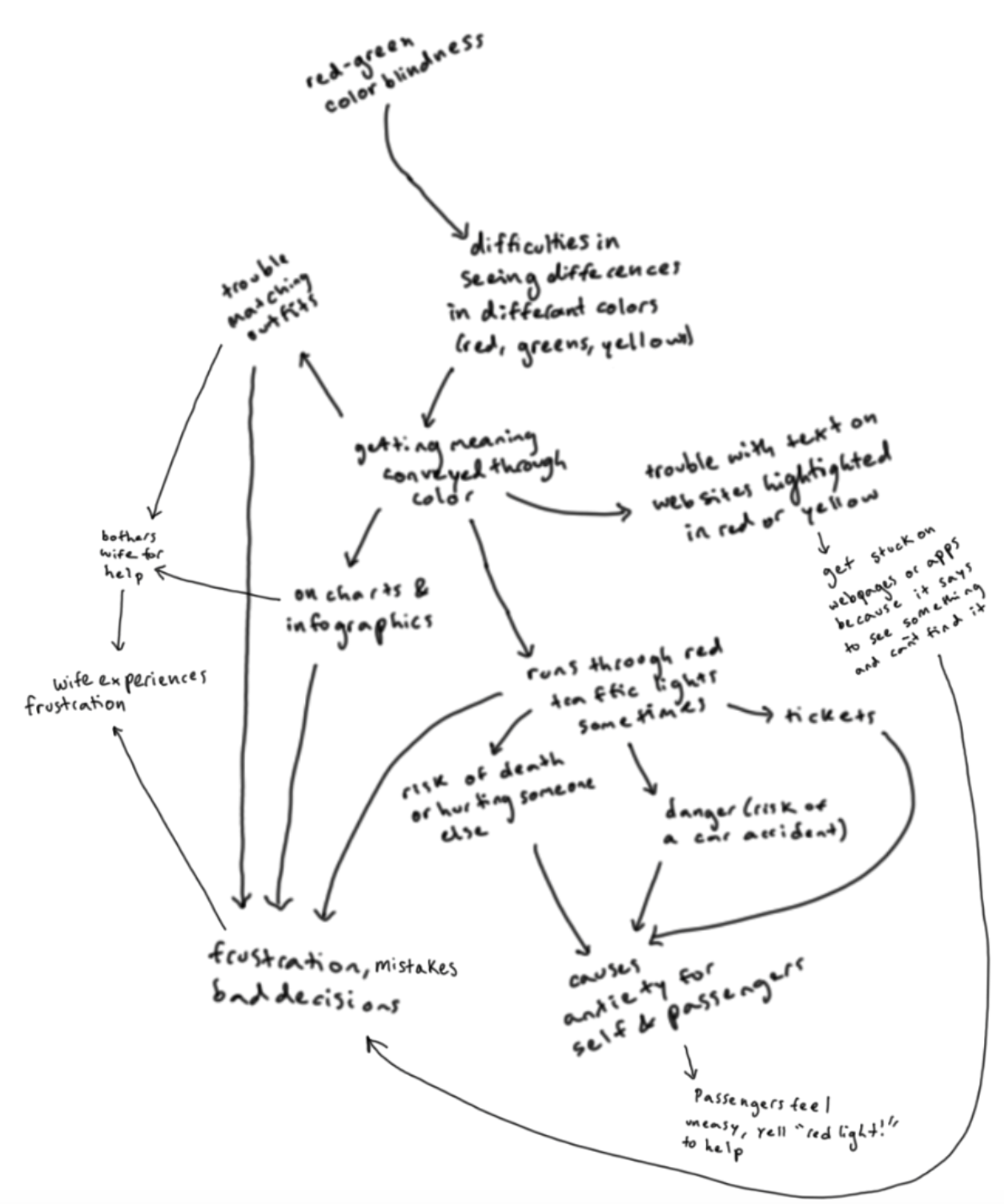
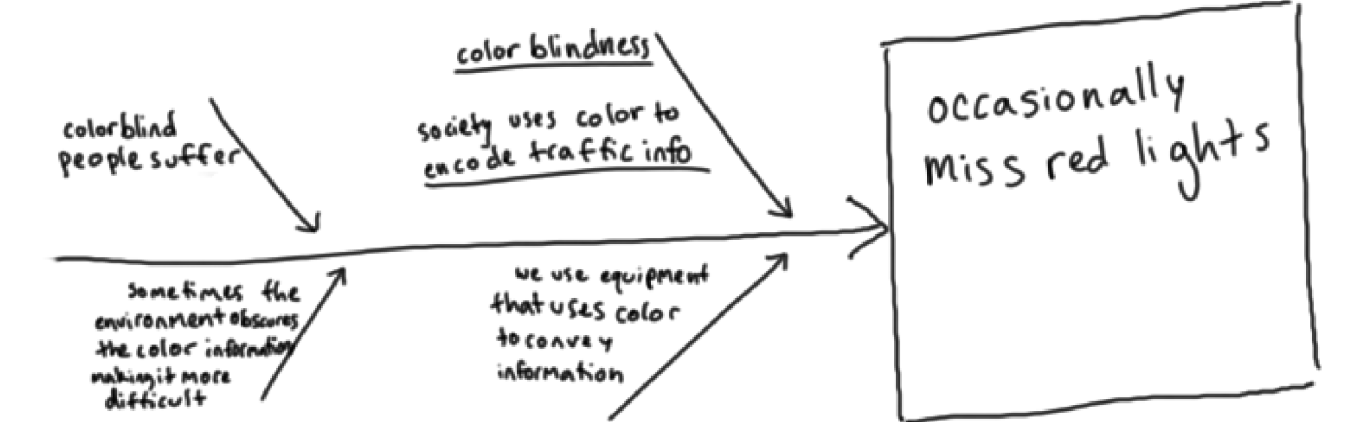
Running red lights is dangerous, but Adam does it more often than most because red lights do not stand out to him like they do to others. This is because he is red-green color blind. This may sound like a not-so-serious issue, since the context of the light on the top of the traffic signal is always the red one. However, since his color vision is impaired, red is not a color that stands out from the background. Approaching an intersection, people with normal color vision are drawn to the green or red signals, as they stand out, like a siren would audibly, to a person with normal hearing. In addition to accidentally running red lights, Adam has been pulled over by police on multiple occasions for running red lights and had to explain that he was colorblind. That he was not ticketed on these occasions is also indicative of the prevalence of this problem. However I am focussing on the problem that one person, Adam, has in regards to traffic signals and seeking a solution. He wondered why traffic lights used red to indicate the need to stop and green to indicate the ability to go when there were no solutions for people for whom red and green do not stand out from the background. His partner has to yell at him when he has been about to run a red light, to indicate that “It’s red, Adam!.” Adam needs another way to know quickly, and in advance when he is approaching an intersection where there is a red light. Stop signs, also being red, do not stand out as strongly to him either, since colors in his world view are not as vibrant and information bearing as they are to me or others with normal color vision.


Dichromatic Red-Blind/Protanopia


Dichromatic Green-Blind/Deuteranopia
Approach
I started by talking to Adam about what problems he wants to solve, and the primary issue that came up was his red-green color blindness. Red-green color blindness, scientifically known as deuteranopia or protanopia, is a common type of color vision deficiency. This condition arises from a lack of or malfunction in the red or green photoreceptors (cones) in the eye, leading to difficulties in distinguishing between red and green hues. As a result, colors that normal vision individuals see as distinct shades may appear similar or indistinguishable to someone with red-green color blindness. This not only makes daily tasks challenging but also puts individuals in dangerous situations, especially when driving. The difficulty in distinguishing traffic lights because of their color was a significant concern for Adam, as it directly affects his ability to drive safely and independently. He shared that his struggles with traffic signals are the moments when he feels most debilitated by his color blindness. This conversation led us to focus on finding solutions that could assist him in identifying traffic signals more easily, to mitigate the risks associated with his red-green color blindness.
My strategy was to start by interviewing Adam to understand his situation. I wanted to learn more about how he experiences the world, so after discussing how some traffic signals do stand out to him, like flashing lights or stop signs with flashing LEDs around them, and how others do not, like traffic signals with pale (to him) colors that blend into the background, I drove around in the car with him and watched as he interacted with traffic lights and stop signs.
I tried to be mindful of my own vision and think about what made traffic signals stand out to me. I looked into what technical methods I could use to get an understanding of his disability. These include applications, like CVS Simulator, which is an iPhone application, that enables normal vision users to see a side-by-side simulation of what a colorblind individual might see. Here’s an example of a traffic intersection, with a red light, passed through this simulator:

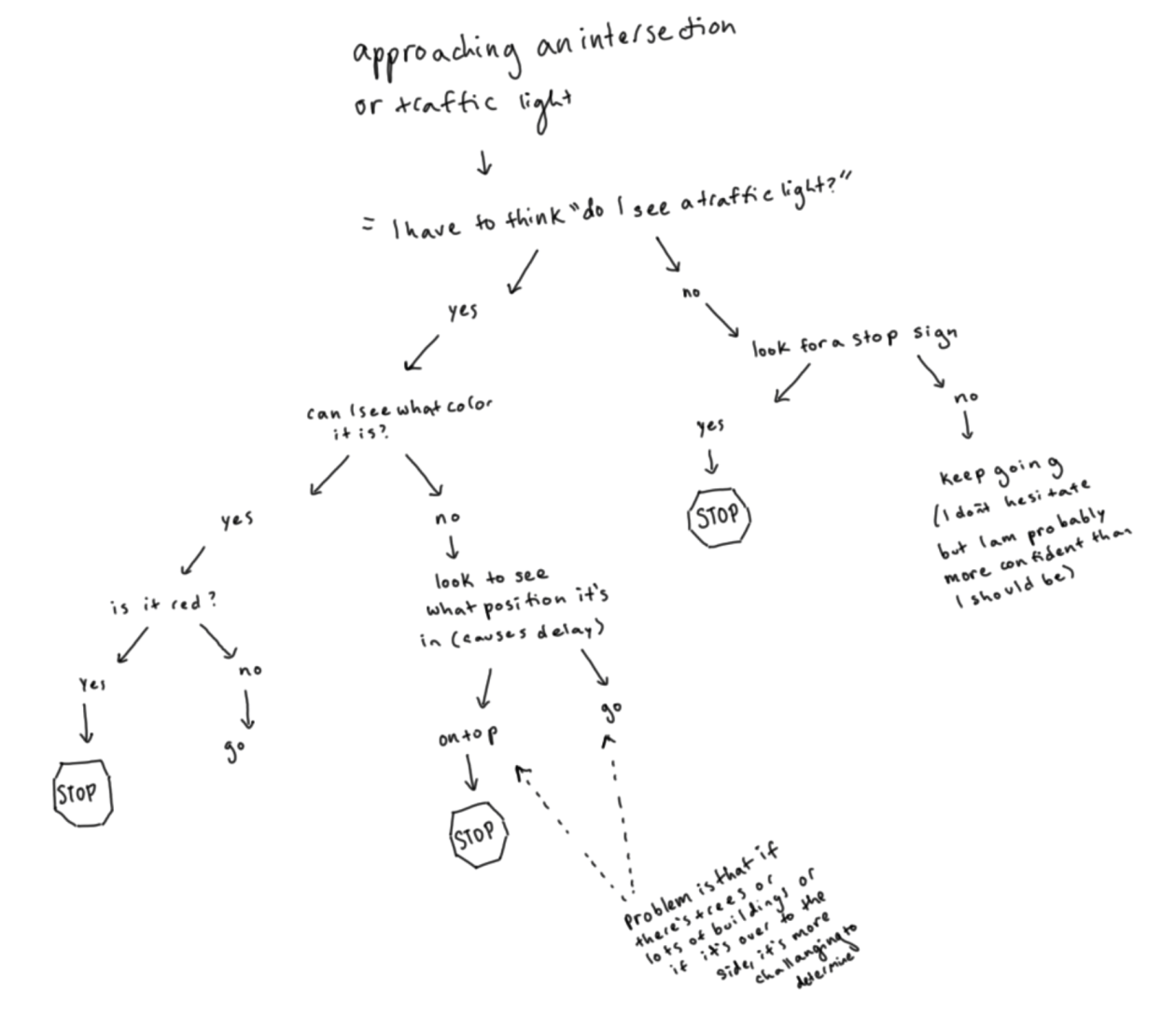
Driving around his neighborhood, I asked Adam to describe what he saw. He told me about the many street lights, traffic lights, store fronts, utility poles, and other elements that came into his field of view while driving. I asked him how he knows when these are traffic lights, versus street lights. He said that he knows this from context traffic lights tend to be in the middle of the road, or on the side at an intersection, but he said this also gets more difficult when an intersection has many lights all combined onto a single pole, or when there are many lights of various kinds in the field of view. Below is an example near Columbia on Broadway, where there are traffic lights, utility poles, street lights and signs all at similar heights in the field of view. To Adam, these all look very similar, and none of them stands out based on color alone. Note that the traffic lights lie in the foreground overlapping buildings, trees, or other elements of the background. To me, when the lights change, the color contrast is vibrant and strong, however to Adam, he sees only a slight change in the background, which hardly stands out. He has to focus on first looking for traffic lights, then looking to see which of the lights on the traffic signal are illuminated, and decode the meaning based on its relative position to the other lights on the signal. In a clear background, without obstructions, this may seem simple, but in a more complicated background, this is not so easy.
Walking down Broadway with Adam, he pointed out places where he could see the traffic lights hanging in the air, and could easily tell the vertical location of the lit light, and how small changes in background made this more difficult. In this example, the left image is normal color vision, the right simulates red-green color blindness. Since there are few obstructions or other lights, if he made the conscious effort to look for the lit circle, he could tell whether it was red, yellow, or green.

Here is the same set of traffic lights, again left is normal color vision, right is color blind simulation. Adam pointed out that for him, at that intersection, even in broad daylight, it was difficult to see the street light illuminated, as it blended into the building. This is the same intersection, a few seconds later from a slightly different vantage point.

Even for me, the image on the right is hard to notice, and the red light does blend in with other elements of the background. When street lights, traffic signals, tail lights, window lights, and shop signs are all overlaid into the scene, I can start to understand the difficulty that Adam experiences in navigating a complex environment and having the traffic signals call his attention.

For stop signs, depending on the amount of traffic, surrounding buildings, trees, and other obstructions, visibility can be difficult even for someone with normal color vision.

Of course it isn’t possible for me to understand how his brain interprets the colors presented to him, since there is far more to color perception than the raw pixel values on the screen below, or the intensity and frequency of light that interacts with the rods and cones in his retina. These signals are sensed by only two of the three color receptors that normal vision subjects experience, and these receptors then send signals through the optic nerve to the brain for interpretation.
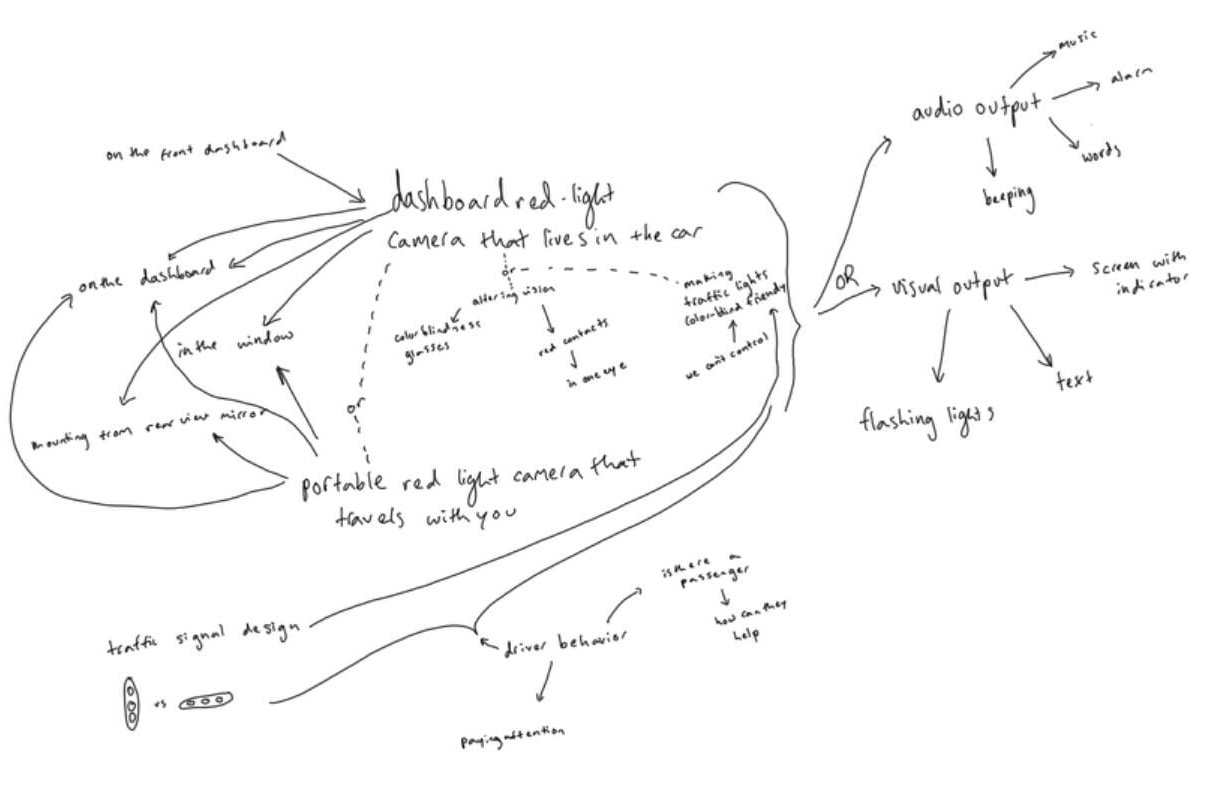
From walking through the streets of New York and driving around with Adam, it was clear that technology that could automatically detect traffic lights and alert Adam audibly, in place of his partner calling out red lights and stop signs, could provide substantial benefit for his color vision.
We brainstormed ideas such as color blindness glasses and red contact lenses, designed to augment color perception for individuals with color vision deficiencies. However, these options presented unexpected drawbacks. While colorblindness glasses have been celebrated for their ability to enhance color differentiation, in driving tests, we discovered they also introduced significant issues for Adam, particularly in affecting his hand-eye coordination and altering depth perception. Similarly, a red contact lens in one eye, though theoretically promising in helping to distinguish traffic lights through a left-right ambiguity, resulted in similar disorienting effects. These outcomes steered our focus toward alternative strategies that could offer Adam reliable and safe navigation cues without compromising his sensory integration or spatial awareness.
First Version
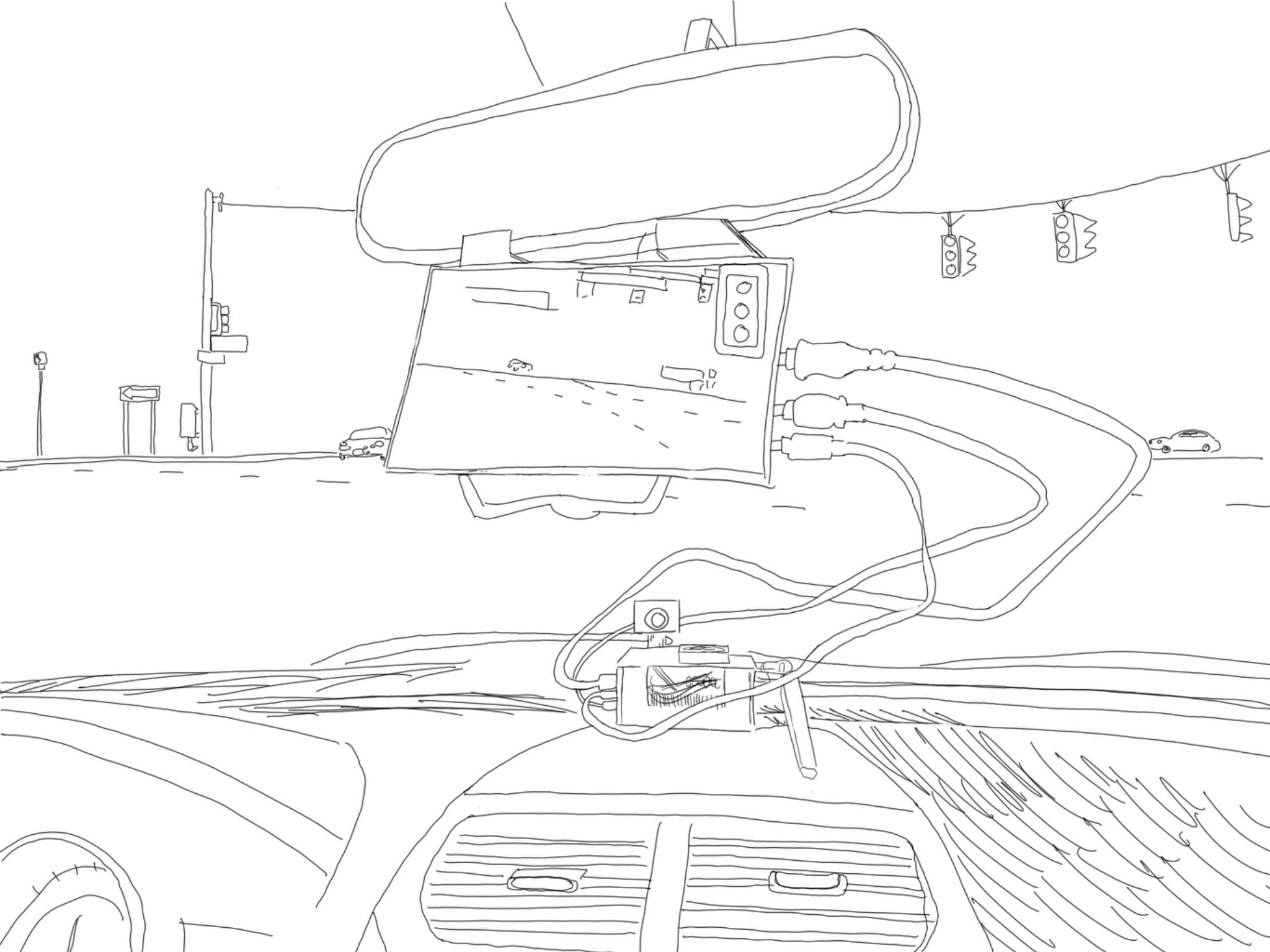
My strategy was to address this challenge that Adam faces due to his red-green color blindness by leveraging computer vision to create a solution designed for him and his needs. I developed an AI object detection and learning system that could recognize traffic signals, particularly focusing on identifying red lights and stop signs to alert Adam when he is driving. My first step was to purchase and assemble a single board computer, the NVIDIA Jetson Nano, with an embedded camera and miniature display. Our idea was to create a device that could live in Adam's car for convenience.

I set up the Jetson Nano developer kit with the Jetpack distribution, which involved flashing the operating system onto an SD card using a computer and then configuring the operating system on the Nano. I installed the computer in an acrylic case for protection. The developer board has various ports and interfaces for easy access, including DC power supply, display and USB interfaces, ethernet port, Micro USB interface, GPIO interface, and PoE interface. Additionally, it featured a cooling fan and support for adding a camera bracket. I installed an Intel dual-band wireless card on the single board computer, and attached Wi-Fi antennas. After installation, I verified the operation of the Wi-Fi and Bluetooth. I cloned a repository from NVIDIA’s Github that contained Docker scripts to run preconfigured containers. I downloaded the Docker container from Docker Hub that was pre-installed with PyTorch and deep neural network models and I installed several pre-trained models from the NVIDIA site. I tested the camera feed and image recognition and object detection using the pre-trained models on some sample images and then on the video feed from my camera, including real-time object detection on the live camera stream, overlaying bounding boxes around detected objects.
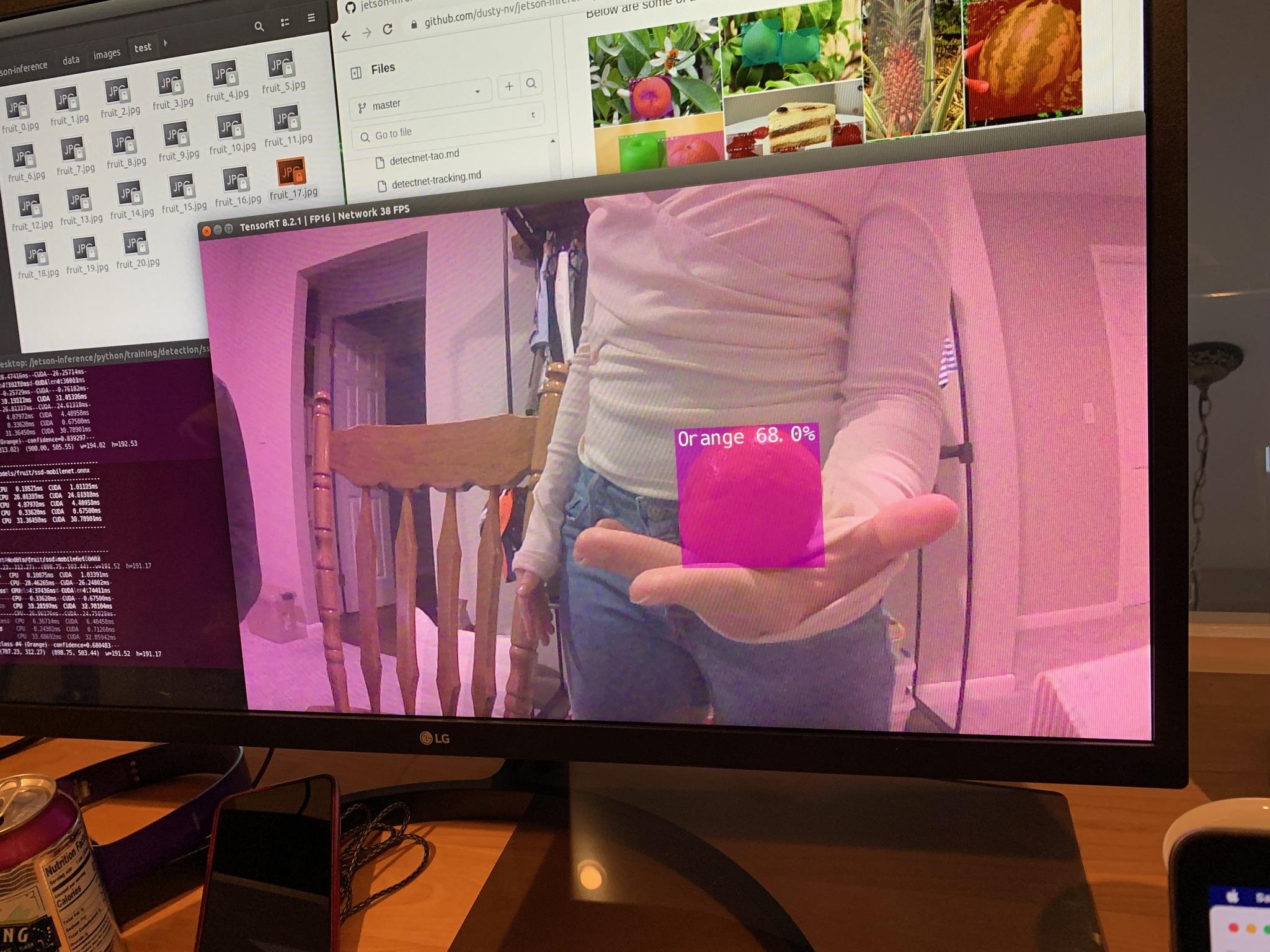
I built and tested an image recognition program using pre-trained models on the Jetson Nano platform. When the image is loaded and the recognition neural network is initialized, the loaded image is classified and this method returns the class index and confidence score of the predicted object in the image. The program prints the classification results with the predicted class name and the confidence score. The command used for testing the model on the test images specifies the model directory, where the recognition model is stored, a labels file containing the class labels used to train the model, input and output layers, as well as the directories containing the test images. I tested the recognition program with pictures of fruit I found online. After confirming that the model worked on the test images, I tested the model on a live data stream from a camera feed.
I created a simple recognition program in Python using a Python script for object detection on a live camera stream. Inside the main loop of the script, I continuously captured frames from the camera stream and processed them using the object detection network. The detect method provided by the neural network object returned a list of detections for each frame. I then rendered the original frame overlaid with bounding boxes and class labels representing the detected objects. I interacted with the live camera feed. I introduced various objects, such as my pet cat and food and household items, into the camera's view to observe how well the program detected and labeled them.
Training a simple classification algorithm

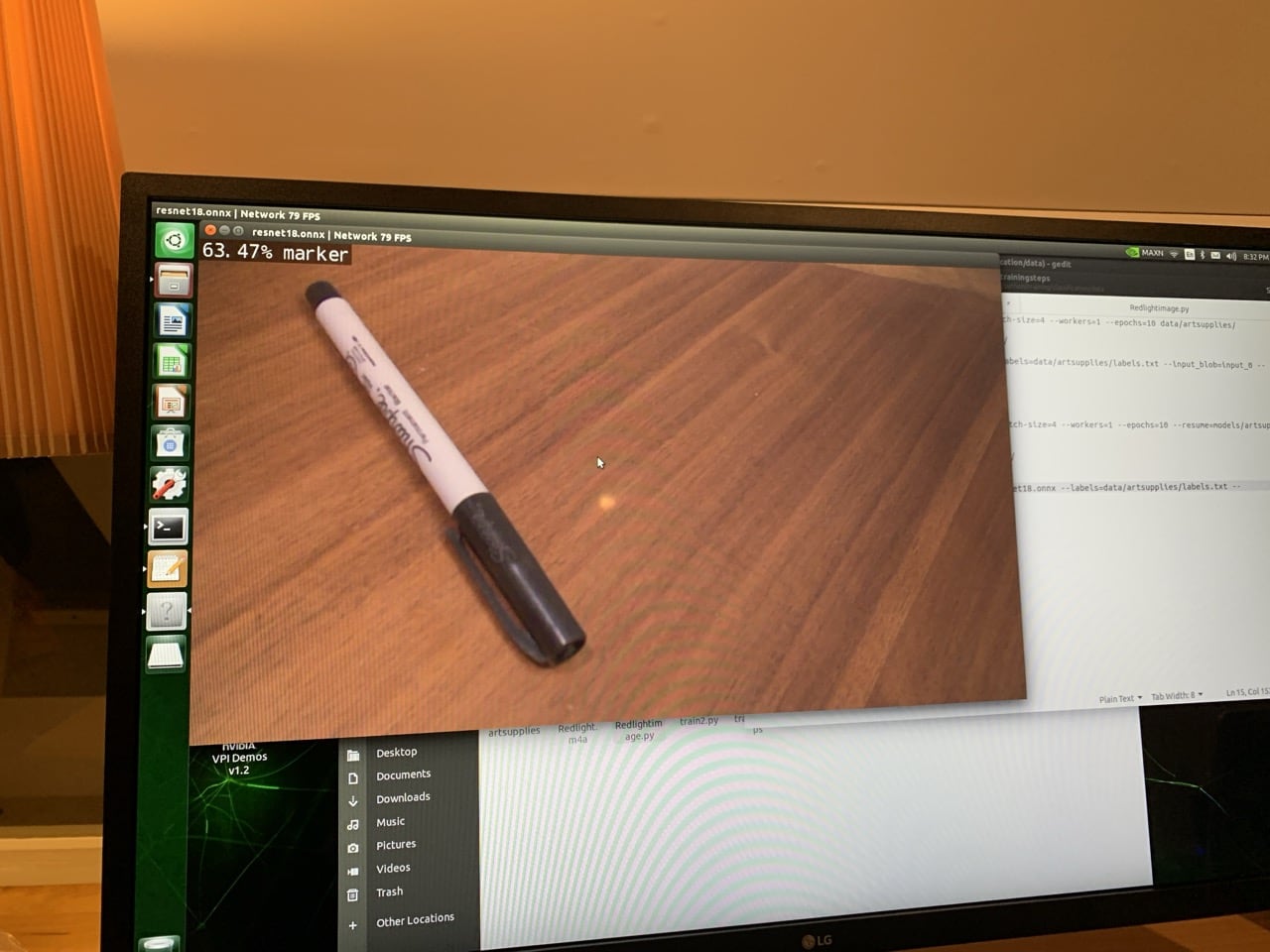
I then retrained the models on pictures that I took of paintbrushes, markers, and scissors from my desk to verify I could do live object recognition on these new objects from a retrained detection model. This process is called transfer learning or model retraining. The object detection program processed frames from the live camera stream and displayed the results in real-time, this time indicating which of the new model classes was present in the frame. I collected a custom detection dataset, retrained the network, and tested its performance on a live stream. I collected 100 images per class, maintaining the independence of the training, validation, and test sets. After collecting 300 images in my custom data set (100 images per class), I retrained the network using the Python script train_ssd.py. I specified the data set type as "voc" (Pascal VOC format) and provided the path to my “brushes” data set. The model was set to be outputted to the "models/brushes” directory. Training was conducted first for one epoch to verify the process, then iterated for 100 epochs to improve training performance.
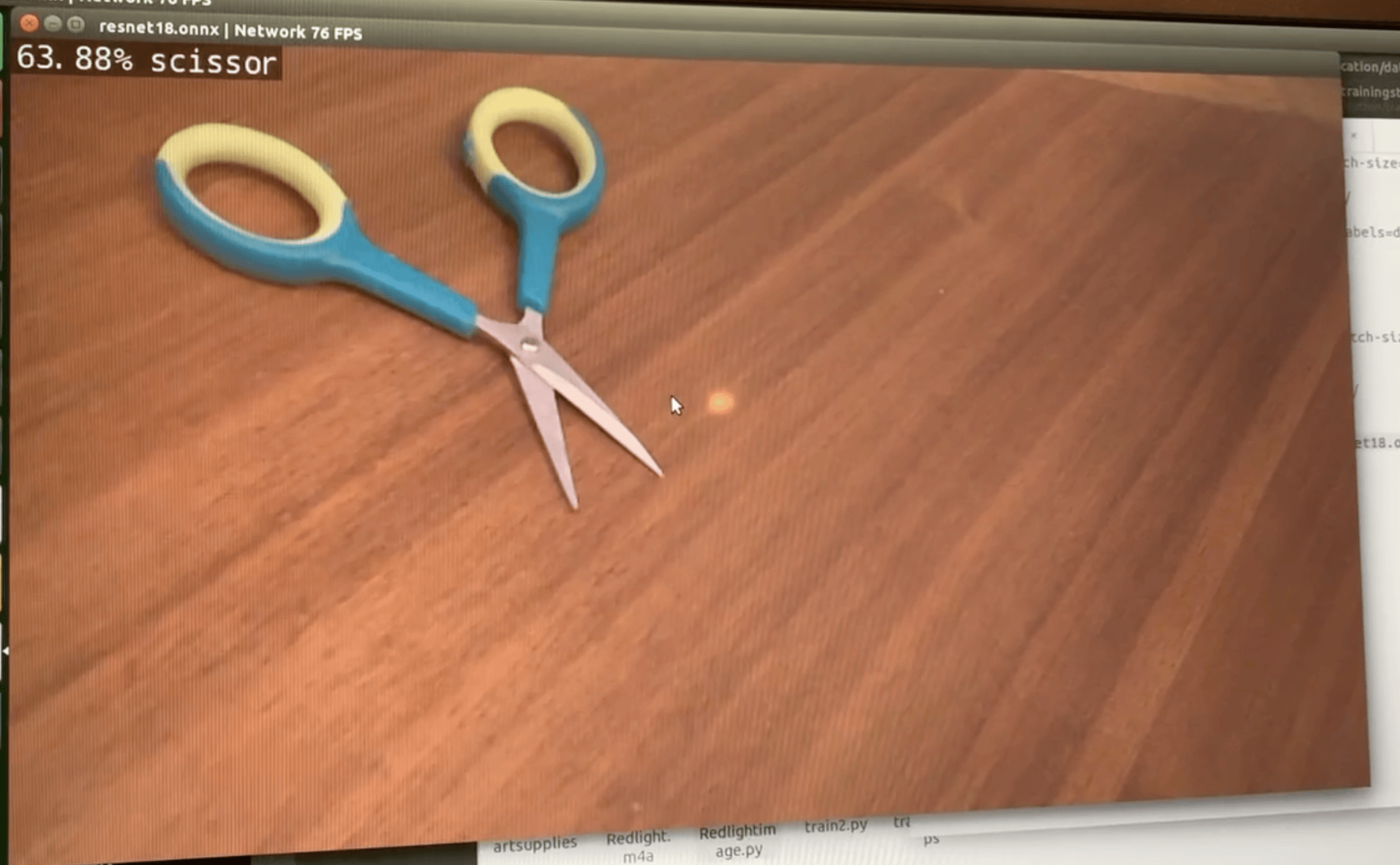
After training the detection model using PyTorch on the Jetson Nano, the next step was to export the model to ONNX format, an interoperable format that allows models to be loaded into TensorRT for optimized performance on a GPU (graphics processor unit), like the Jetson Nano. Once the model was exported to ONNX, the next step was to test the model on the test images from the dataset. I tested its performance on a live stream from my camera device and verified that the network was able to accurately detect objects from the custom classes I trained it on, even in scenarios with multiple objects in the frame.
Then, I collected traffic images I took myself in Adam's community and downloaded a set of traffic images of traffic lights and stop signs from a data repository, converted the file structure and repository contents to match those needed for the Jetson model training algorithms, and retrained the model with this data set. This involved sorting the images into training, testing, and validation sets, each of which includes the images, along with annotations that contained the object labels that correspond to each image and a bounding box identifying the object location within the image. I created a new directory for this data set named “traffic” and generated a labels file containing the names of the object classes. After repeating the process with this traffic data set, I tested the model using a live camera feed, while viewing many of the images in the data set on my computer screen. When this proved to be working properly, I added a voice-over to my detection script to play adam’s partner's voice saying “red-light” each time the detection algorithm returned a detection of a red traffic light in the image frame, and “stop sign” each time a stop sign was detected.
We tested this setup, using the Jetson Nano platform with a connected USB video camera on the dashboard of Adam’s car, and drove around through areas with traffic lights, stop signs and plenty of other traffic and distractions. We also drove Adam's daily commute back and forth. While the algorithm worked well in some situations, the glare from sunlight into the camera made the detection algorithm fragile and missed many stop signs and red traffic lights. Also, the form factor of the jetson nano computer with video camera and mini display was cumbersome and difficult to hold in one place while driving. The traffic light detection model on the Jetson used the “single snapshot detection” or “ssd” model as the baseline pre-trained model, before my retraining with the traffic dataset. I decided to look for additional traffic data to either retrain my ssd model, or leverage a different detection platform for a second test.




Second Version

I found a substantially larger traffic data set that was configured for the YOLO (“you only look once”) neural network model and a pre-trained YOLO detection model based on this data set. As a second test, I decided to try a YOLO detection model embedded in an iphone application, written in swift, and distributed by Neuralception. I downloaded and built the application from their published github and made modifications to the iphone app source code to provide an audible alert on the identification of the class “traffic_light_red” or the class “stop_sign”. This model used the iphone camera and screen and performed better than the one that used the Jetson Nano and usb camera. Working closely with Adam, we identified ways to optimize the system for his use. We conducted many trial runs in the car, evaluating the effectiveness of the solutions and refining them based on their performance. I focused on personalization and aimed to craft a solution that not only functions effectively but resonates with the biggest challenge that results from Adam’s color blindness. Between times Adam and I tested the system together, he used it daily on his commute and took notes on his feedback. He found that a controllable volume audio alert, together with a large stop sign image or red light image superimposed on the phone’s screen provided the best system for his use. He preferred beeping over his partner's voice repeating the same phrase. Snapshots of detected stop signs and red lights are shown below.


While the stop sign and traffic light icons were helpful, the image annotations of other objects detected from the YOLO traffic dataset were distracting, including cars, pedestrians, and other objects. I modified the iphone application to remove all image annotations, but to keep the stop sign and traffic signal icons in the top right corner of the video screen. With the camera wedged between the windshield and the dashboard as shown below, we tested the system again.

This was much improved, providing accurate detections of stop signs and red lights, however the system also detected other objects as false alarms and often signaled that a stop sign or red light was present when either it was not, or when there was a stop sign on an adjacent road, not facing the driver. I adjusted the threshold used in the application to only accept detections of stop signs and red lights when the confidence level of the detection was above this higher threshold. This eliminated false alarms, but when a stop sign was in one frame of the video, it would remain there until it was passed, and the alarm signal repeated continuously. A further refinement of the application, included inserting a time-stamp in the detection objects which was set with the time that the object first was alerted to Adam. Subsequent detections then would not be reported (or sound the alarm) until at least 3 seconds had passed. This final refinement made the operation clear, but not overwhelming. I created an icon for the application that superimposed a stoplight on a stopsign. I purchased a mount for Adam's phone as part of the final set up.
Outcome
The project overall was a success, in that we were able to clearly demonstrate that a computer vision system can improve the safety of driving for Adam, especially in busy intersections, with many lights and overhanging structures. Stop signs and traffic lights are detectable and an alert to the driver can be easily implemented. Improvements to the system could include integration into the car lane-keeping camera system, which many cars have, including Adam’s as well as incorporation of GPS data into the operation of the system, so that traffic signals and stop signs that are not directed toward the driver don’t cause false-alarms, as they still occasionally do.
Adam now uses the app daily.
Final app

Bill Counter

Collaborator: Luke, John (Names changed for privacy)
Problem
Luke has dementia. He likes to check on his money and he has trouble counting the bills that he has. When I asked what he would like me to make for him or what problem he wanted me to solve, he said that he wanted to know how much money he had and that he wanted to know what his mail said. Spending time with Luke, I see that he is frustrated by not being able to do many of the things he used to take for granted, and he often finds it difficult to convey what he wants to say. Although he is in his 90s, has poor vision, and is missing a thumb, Luke loves to go bowling. It is one of the pleasures of life that he retains, and it is an opportunity for him to leave the house and do something he has enjoyed for decades. He will often bowl over 100. When Luke isn’t sure that he has enough money for bowling, he can get nervous and asks to make sure that he has enough money and he likes to see it counted, even though he has difficulty doing this himself. He told me that he would rather not have to ask. His wife passed away recently and he has a live-in aid, but he prefers to be able to check on things independantly. He doesn't want to always have to ask for help.
Approach
My strategy was to observe Luke in his home and identify activities that gave him pleasure and those that gave him stress and difficulty. One that gave him pleasure was going bowling and knowing that he had the dues that he needed in order to go. One that gave him discomfort was not being able to count his money for bowling and tipping workers who came to the house to ensure that he had enough. Since his vision and counting skills have diminished, he and I decided I would create something that tells him how much money he had. I decided to use a computer vision system to count his money for him, and tell him how much he had by simply laying his bills on the table in front of a camera.
I tried to be mindful of his willingness to use technology and found that he was comfortable with using the television and with using simple electronics, like a remote control for the television, or the telephone.
My intention was prototype a few ideas to see what could work, and provide this service for Luke’s benefit and to put his mind at ease. While he often asked his caregiver to help him find and count his money, he prefers to have the satisfaction of doing this himself.
The first step was to observe Luke going through this process and see what aspects of the problem were easy for him, or those that gave him pleasure. He enjoys holding bills in his hands, laying them down on the table and then picking them up, one at a time, folding them, and putting them into his pants pocket.
Knowing that Luke enjoys laying the bills on the table, I decided that this would be a good opportunity to create a money counting system that used computer vision to identify the bills on the table, take note of their currency values and add up the total.
First Version
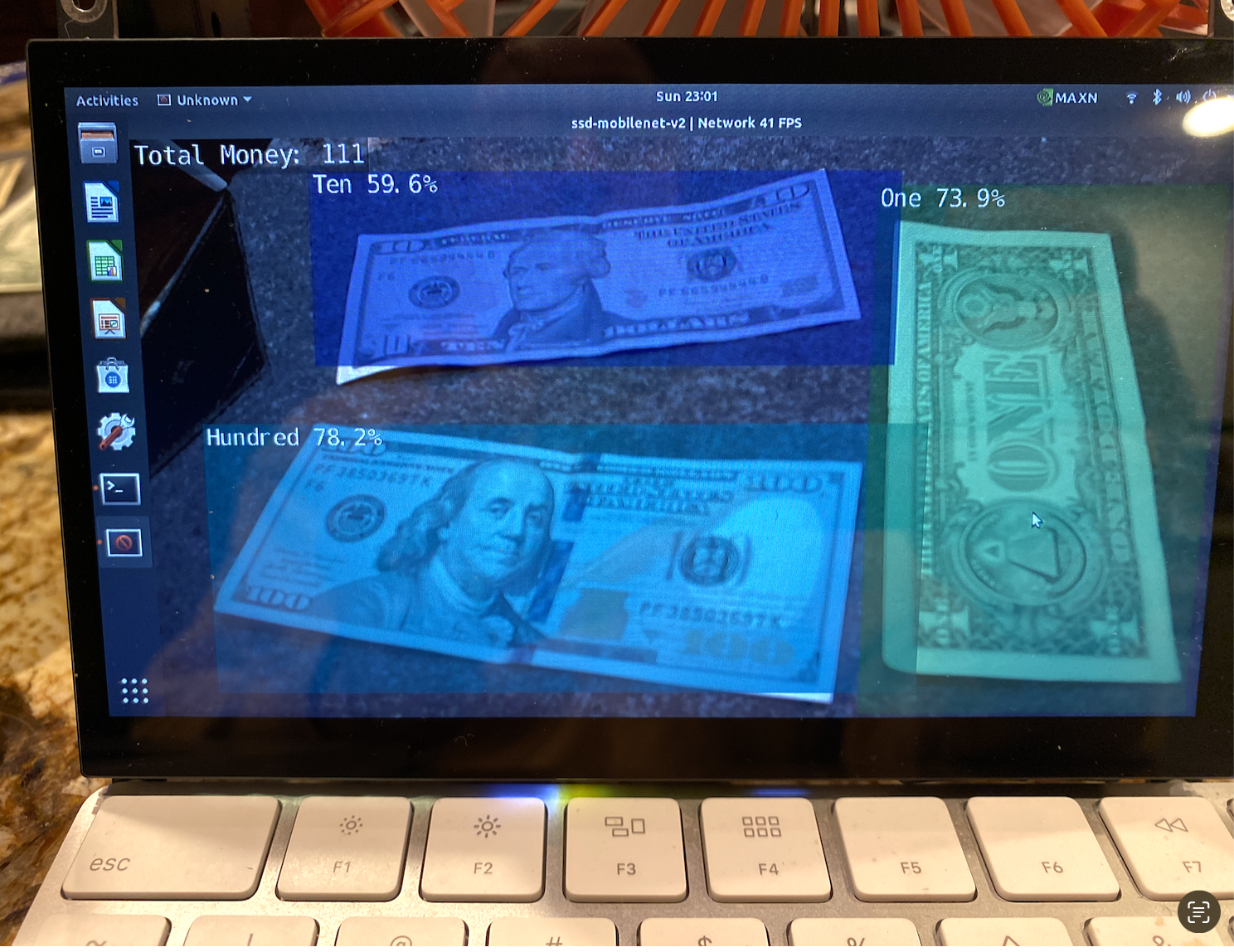
Because Luke likes to lay his bills on the table and has memory problems, I thought it would be best to make a device that could be set up in the same place in Luke's home on a table that could always be there. To accomplish this, I bought a second NVIDIA Jetson Nano. I decided to use a the NVIDIA Jetson Nano single-board computer system and camera, since the Jetson is equipped with a powerful GPU for computer vision tasks, but has an overall small footprint. I used several different bills of different US currency denominations, and took many images of the front and back of each bill. After taking each photograph, I annotated the files with bounding box information, using a data collection routine that is part of the Jetson Jetpack software distribution for the NVIDIA Jetson Nano. I separated the data into train, test, and validation sets, and put the file labels and photograph annotations in a directory structure to enable training of the ssd-mobile object detection neural network module. The process of training the object detection network for 10 epochs includes 10 passes through the training data, evaluating the detection performance on the labeled training data and adjusting the parameters of the model to better fit the training data using automatic differentiation tools, through a process known as gradient descent. Over many training epochs (or iterations) the error of the algorithm gradually decreases, like sliding down a hill, corresponding to the loss function that is optimized by the training algorithm. After 10 epochs, I converted the resulting training model into the ONNX format conducive to detection on the Jetson Nano. I then tested the object detection algorithm to see how well it was able to detect and recognize individual bills. The performance was good, but occasionally made errors identifying a ten dollar bill as a one dollar bill or vice versa. I decided to train the network again, this time for 100 epochs. After an additional several hours of training, I repeated the tests and verified that the performance was good enough to accomplish the task of helping Luke count his bills, though a larger data set (more images), and more training epochs would improve performance. To avoid double-counting of bills, I only included bills detected with a confidence level above a certain threshold, and also compared the bounding boxes around detected bills, only reporting the bill with the highest confidence when two detections were made with overlap that exceeded a certain threshold.



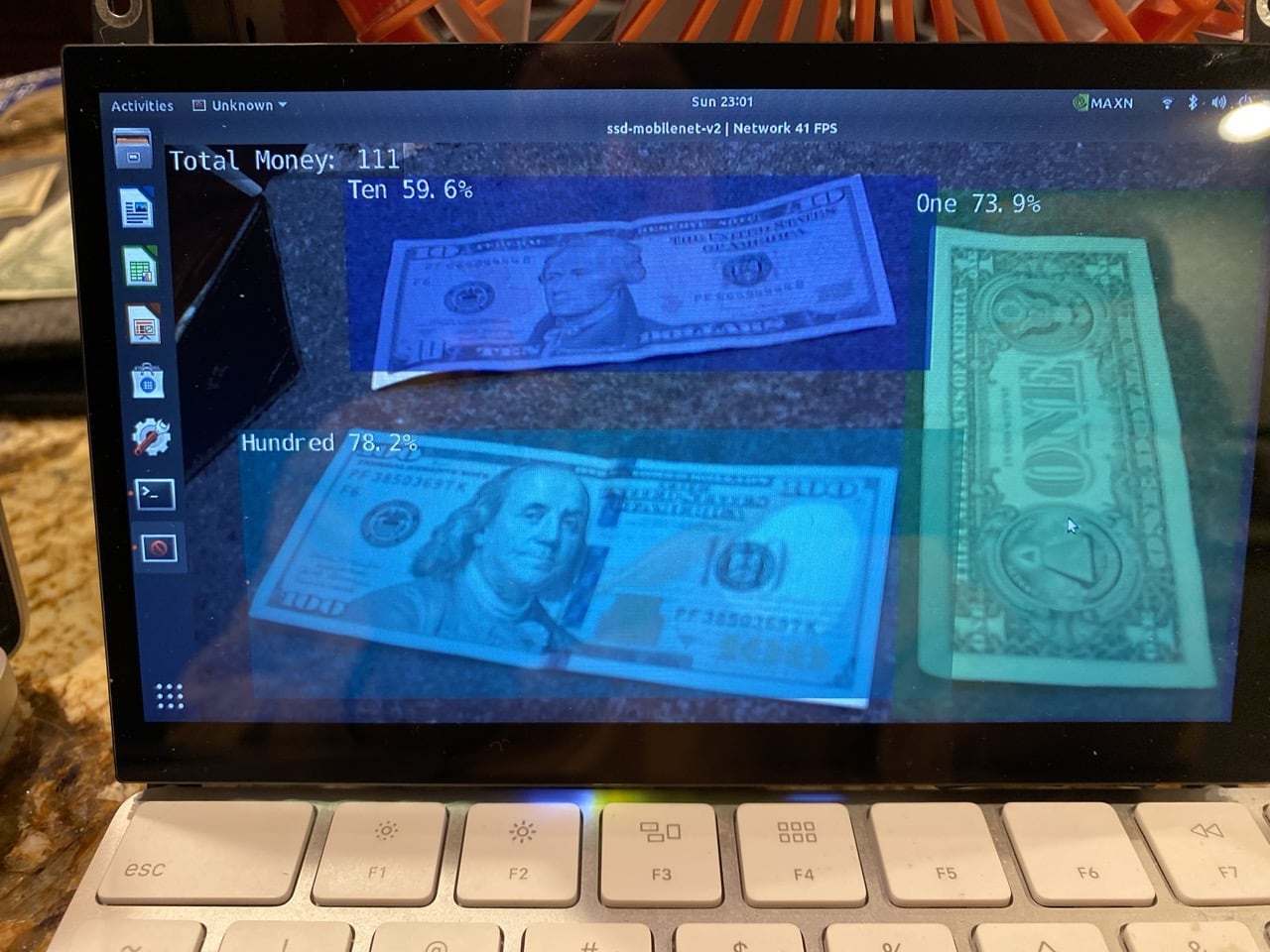
I had Luke place his bills in front of the camera and watch as the screen captured his bills and told him the amount of money. He was pleased with the outcome, but had trouble seeing the screen. The next step in the process was to add text-to-speech, using Google’s gTTS package in Python to the system, so that it can read the amount out loud. This was easily accomplished using the Google cloud-based text-to-speech (gTTS) library eliminating the need to read the total on the screen.





Second Version
To simplify the process, I decided to see if I could make a version of the money counting application run on my laptop in python. I found a YOLO model that was hosted at ROBOFLOW that was trained on US currency, and had an API interface available. I was albe to use essentially the same python code from the Jetson, substituting an API call to the ROBOFLOW based YOLO model for the bill detections, and again used text to speech to speak the amount of money detected, as well as display the total on the screen. This was still a bit clunky, in that I needed to setup a webcam to point at the table, and put the bills onto the table to be counted. I also needed to have the user hit the ‘t’ key to total the money.


Luke decided he only wanted the computer to tell him the total amount, not what each bill was before the total amount. This was easier for him, so we adjusted the device accordingly.
Third Version
This prototype arose due to the needs of another family member, John. I had told him about the device I had made for Luke, and they had similar disabilities and were interested in something similar. Unlike look, this family member had an iphone and was comfortable using it. For them, I decided to create an app. I built on the ideas in the Traffic Assistance program, and created an iphone app using SWIFT to essentially replicate the python code running fully on an iphone. When the application starts, now, by pointing the phone at the money and tapping the screen, the phone takes a photo, sends the photo to ROBOFLOW through the API, and reports the detections back through the API. The labels for each detection are matched to their corresponding currency, and the values are summed to give the total amount. This amount is then both displayed on the screen in a small window above the photo, and spoken out loud through text to speech. After a few seconds, the system is ready to count again. I made an icon for the iphone app that has a cartoon image of dollar bills. We worked together to adjust the UI and voice on the app to fit their preferences.
Fourth Version
Over many iterations, John and Luke expressed their preferences in voice and voice speed and information given, which was reflected in their respective apps and devices.
Building on the use of an API call, I experimented with sending the image directly to openAI’s GPT4 model to see how well it could discern the contents, with a query saying “the uploaded image contains US currency. Can you tell me how much money is in the image?” and then the response could be played back directly using text to speech on the iphone. This worked reasonably well, though was about as consistent as the roboflow-based model.
Outcome
The project was a success, in that it was able to help Luke and John member to check the amount of money they have in bills at any time. However, any new technology is difficult for Luke to completely understand. He was excited to see that this was possible, but in its first prototype form, using a Jetson Nano single board computer and screen, the solution was a prototype of what could be made into a fully-enclosed solution. The subsequent versions using the laptop, and then finally the iphone made the operation an easy-to-use success. Not only can Luke use this for counting his money, but John can as well. John has similar disabilities, both visual and cognitive that make counting money difficult. John uses his iphone often and really likes that interface. For luke, I set up a table and we decided to use a big red button so it's obvious what he needs to press to make it work, even if he forgets. There is only one button so it is very clear. It is big so it is easy to use. I put it on a small table by itself in a place near where he likes to sit so he knows where to go. The device I made using jetson works best for him because he is not comfortable with an iphone. We used tape to mark where he should put the money. His aid knows how to turn it on and off. Luke has said he likes his money table and his aid has said he will often get up and use it instead of giving her his money to count.
The final set up:
Process
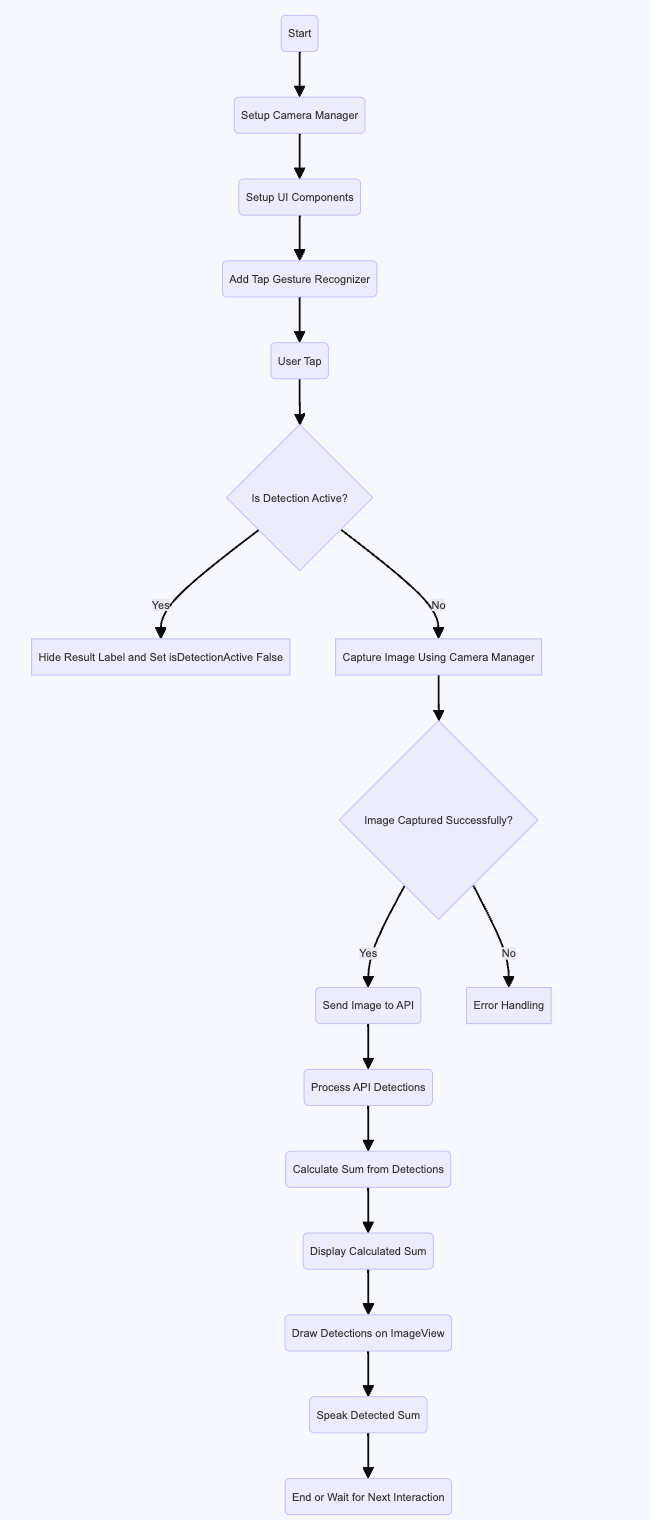
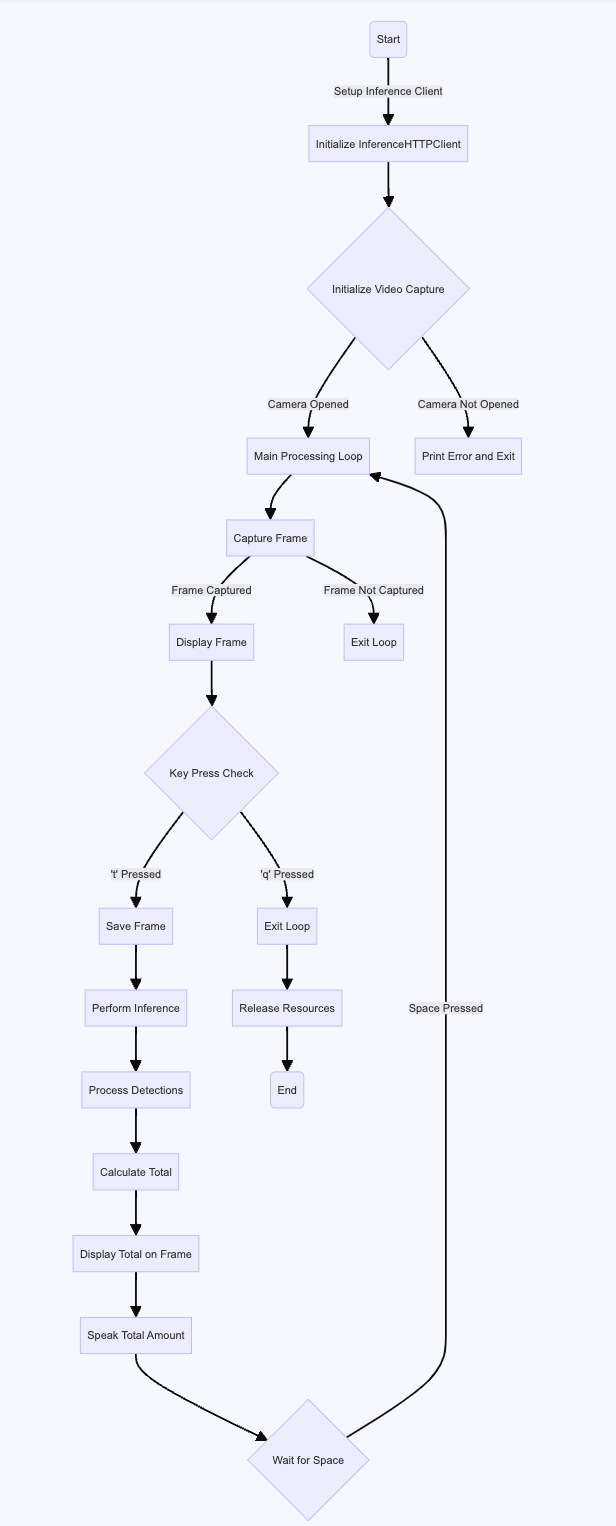
Swift code version of bill counter Python version of bill counter
Setup for taking images of bills and tagging them with the proper label and bounding box with different orientations.
Example showing testing of the detection algorithm with the trained network
More examples of testing on the trained model
More examples of refining the training and performance of the detection algorithm with multiple bills in the image
Example showing the summing of the detected bills and displaying the total as an overlay
Final set up:

Reading Assistant
Collaborators: Luke, John



Problem
For some people with limited vision or intellectual disabilities, reading complex signs or other printed material can pose a substantial barrier to accessing services or gathering information intended for them. For Luke, a frustrating aspect of aging and experiencing dimentia, is feeling of a loss of control. Even though his caretakers read and sort the mail and takes care of what needs to be taken care of, he feels that it is his mail and he wants to know what is going on. He told me that he doesn't want to be told not to worry about it and he doesn't like needing to ask what it says.
Approach
To approach this problem, I again evaluated the impairments and disabilities of the individual. Luke has difficulty reading signs or letters addressed to him that may have important information in them. He wants to be able to read his letters. Observing Luke in his home, I saw that he would look at mail, but would get frustrated if could not really understand what was sent to him. The problem here was not only identifying the material of interest, but also summarizing it and relaying that information back in an easier to understand form. I decided that both written summarization and voice-feedback might help Luke better understand the material and signs that he was attempting to interpret. He enjoyed the voice feedback for the bill counter, so I hoped for similar success with the reading assistant.
For detecting the information that is relevant in a letter, document, advertisement, or sign, I opted to follow the theme of using computer vision and machine learning methods to provide help these disabilities with seeing, reading, or summarizing complex written and visual information. For this task, fast optical character recognition algorithms can be used on frames taken from a video camera feed. While this information may be somewhat error-prone, a subsequent pass through a Large Language Model, like OpenAI’s Chat-GPT, can apply an english language context model to extract the meaning from the extracted text.
The extracted and corrected text, however, is no better for Luke than the original document or sign. The difference here is that the Large Language Model can now be used as generative-AI to produce a response to a query detailing Adam's needs around how to simplify and summarize the information. Note that this step is tunable, and the query could be adapted to the target user of the sign overlay system. In Luke’s case, I opted for a query that asked for information that provided enough information for him to understand, but not so much that might confuse him.
The last step is to then provide this information back to Luke. This was accomplished by first overlaying the summarized information, in large font, over the image of the document or sign to be interpreted. To further aid in comprehension, a text-to-speech engine was used to read the summarized information back.
I used python as a computing environment, and wanted to connect to the OpenAI chaptGPT engine for summarization of complex information at a level that could be understood by someone who’s disability was described to chatGPT. This required a slightly more powerful computing environment than the edge computing resources in a Jetson Nano, as the openAI API layers were not yet available to the Jetson Nano. Also, since part of the interface for this will include a larger screen, I opted to use a laptop computer as the host.
The OpenCV package enables accessing input video streams from python using a USB or screen-mounted video camera. OpenCV similarly enables opening a video output feed on an attached monitor or laptop screen. Once a frame was captured from the input video stream, I used the pytesseract package to perform optical character recognition (OCR) on the image frames and output a list of lines of text found in the frame. These include real text, along with scattered numbers and letters found within the frame or mistakenly identified within the frame.
Using openAI’s API (application programming interface), these lines of text can be processed to extract semantic content and then summarized. To do this, I passed the text through the API call and posed the a question to openAI’s generative AI (Chat GPT) asking it to summarize it so that someone with my grandpa's symptoms could understand, followed by the text extracted from the video frame. The returned result from the query is a data object from which the text of the response can be readily extracted.
To convey the response, now a re-framed, summarized, version of the information framed such that he could understand it, both display, and voiced the response. To display it, I used a large text font, wrapped such that it would fit well within the display, and overlaid this on the screen together with the original image from which the text was generated. To add voice to the text, I used Google’s gTTS (google text to speech) package to convert the text to speech and read it to the user.
Testing this system out, I needed to test the timing between grabbing an image frame, processing and displaying it, and processing the next frame. I found that continuous operation updated the screen too often for someone who might need time to process the displayed information. To simplify this process, I added two buttons to operate the system. First, aligning an image to the camera, the extracted, but unprocessed text can be seen overlaid on the image, when the user types the “T” key, this is translated, overlaid, and read aloud. The system then freezes the image for five seconds, though this amount is programmable as well. The “Q” key can be hit at any time to quit the program. On subsequent iterations, I added black boxes around the text, so that it was more legible, used a bold font, and simplified the display to only show text when it is prompted by the user with the ‘t’ key.
Once this worked well, I then switched to the same big red button idea as used for the bill counter, because that had worked well for Luke for the bill counter. Luke and I iterated on the speed and voice of the speech to find one that was comprehensible to him that he liked.
Second Version
Since John liked the app version of the money counter I had made for luke, I asked if he might like an iphone version of the reading assistant as well. He agreed. After successfully implementing the system in Python, I was able to develop a version running on the iphone, using SWIFT essentially mirroring the flow used in the python program. Rather than using the ‘t’ key to grab the image for translation, in the iphone application, the phone continually shows what the camera is pointing to, and by tapping the screen, a photo is taken, and this photo is then processed with OCR to extract its text, and an API call is made to openAI for summarization. On return, the text is read aloud with text to speech, and the text is overlaid over the image on the screen. After a few seconds the application resets and is ready for another image. For this iphone application, I created an icon for the app that resembles an overlay graphically.
A control flow for this application both in python and swift are shown below
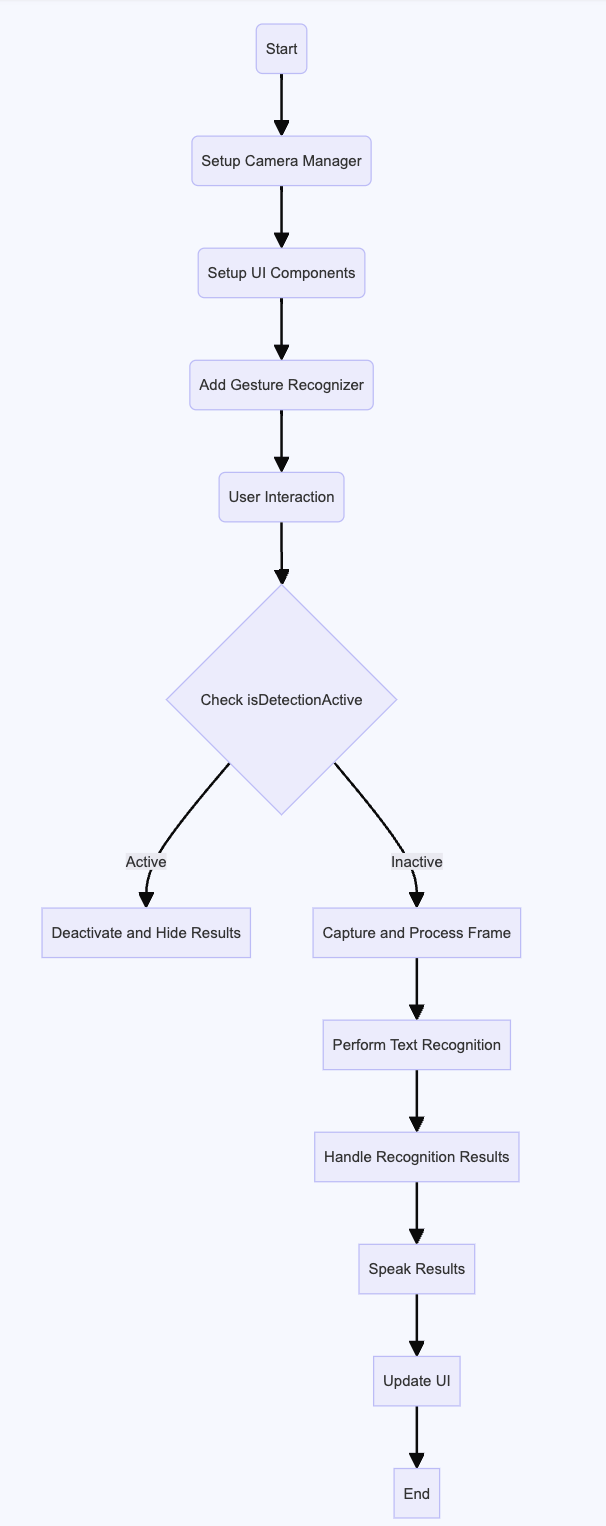
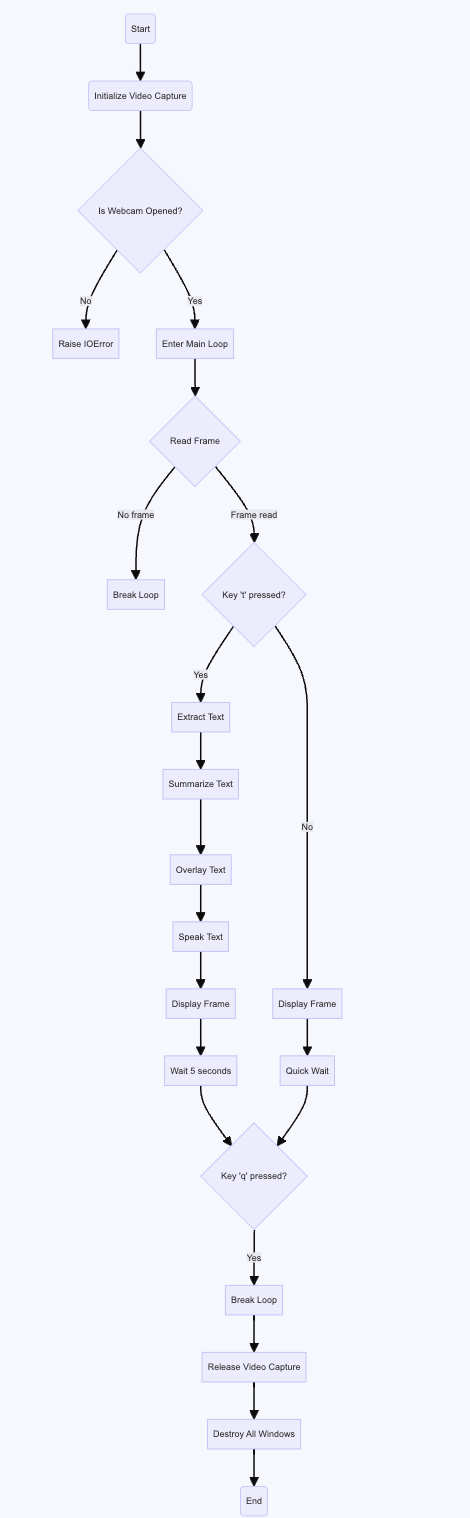
Swift reading assistant flow graph Python reading assistant flow
Outcome
Luke uses his station with the big red button to read his mail. He says he likes it. I know it works for him because in one of our last experiments testing it, as soon as it read the letter to him about a problem on his property, he started talking about what he would do to fix the property. I think he's happy to feel like he can be more involved by himself. I put the matching app on John's phone. He is testing using it and giving feedback as well.
Conclusion
These are three examples of a design-for-one perspective, leveraging mobile technology, computer vision, and machine learning. What’s next is to allow the users to continue to live and work with these solutions over time, and explore how they are able to benefit from them as well as areas of unexpected difficulty or ways that these solutions could be improved. We’ve iterated on these solutions for months and will continue to do so over time. I’m publishing these solutions, and descriptions of the benefits made available through them, which may enable similar design-for-one solutions to be enabled for others. The methodology used in these case studies can be readily replicated, as I have done three times, and my hope is that, just as was the inspiration for this project from the beginning, that members of the disability community are valued as the experts on designing for their own disability, and those with disabilities and their loved ones can learn from these examples and innovate based on the machine learning and computer vision technologies demonstrated here.
Notes on the Methodology
The problems that each person brought to me all happened to be vision related so I ended up with this portfolio of computer vision projects, not because I imposed computer vision as the methodology, but because I listened to what they were struggling with and what they asked for and they were all vision related and I just saw that as an opportunity. The common methodology that was followed for all three examples was to use a user study to evaluate and understand the needs of the user, followed by rapid prototyping of various approaches to providing solutions using python with computer vision, AI, and machine-learning packages. Once a viable solution was functional in python on a laptop or single-board computer, these could be readily ported to a mobile app on an iphone.